HybridVLA:
Collaborative Diffusion and Autoregression
in a Unified Vision-Language-Action Model
Demonstrations
Generalization
Abstract
Recent advancements in vision-language models (VLMs) for common-sense reasoning have led to the development of vision-language-action (VLA) models, enabling robots to perform generalized manipulation. Although existing autoregressive VLA methods leverage large-scale pretrained knowledge, they disrupt the continuity of actions. Meanwhile, some VLA methods incorporate an additional diffusion head to predict continuous actions, relying solely on VLM-extracted features, which limits their reasoning capabilities. In this paper, we introduce HybridVLA, a unified framework that seamlessly integrates the strengths of both autoregressive and diffusion policies within a single large language model, rather than simply connecting them. To bridge the generation gap, a collaborative training recipe is proposed that injects the diffusion modeling directly into the next-token prediction. With this recipe, we find that these two forms of action prediction not only reinforce each other but also exhibit varying performance across different tasks. Therefore, we design a collaborative action ensemble mechanism that adaptively fuses these two predictions, leading to more robust control. In experiments, HybridVLA outperforms previous state-of-the-art VLA methods across various simulation and real-world tasks, including both single-arm and dual-arm robots, while demonstrating stable manipulation in previously unseen configurations.
Video
Overview
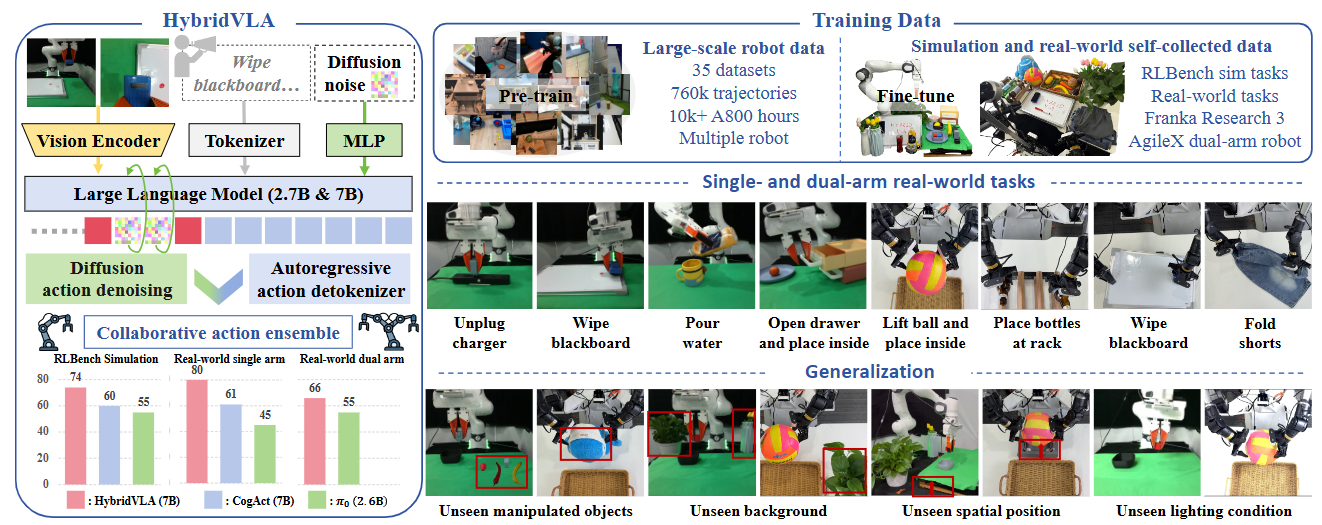
HybridVLA innovatively integrates diffusion and autoregressive action prediction within a single LLM, fully leveraging the continuity and probabilistic nature of diffusion alongside the reasoning capabilities of autoregressive modeling. It undergoes pretraining on large, diverse, cross-embodied real-world robotic datasets and is further fine-tuned on both simulation and self-collected real-world data. HybridVLA achieves remarkable performance across various tasks, demonstrating strong generalization to unseen manipulated objects, backgrounds, spatial positions, and lighting conditions.
HybridVLA Framework
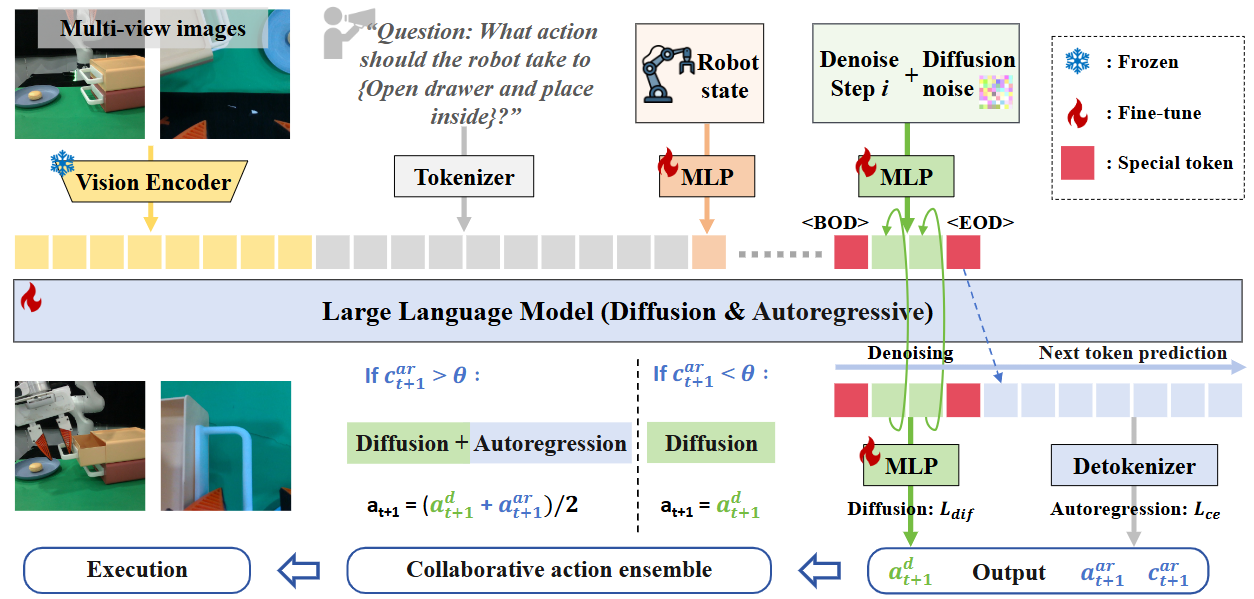
The input data, regardless of modality, is encoded and concatenated into our formatted token sequence. To integrate diffusion into the LLM, HybridVLA simultaneously projects the denoising timestep and noisy actions into the token sequence. The marker tokens, $<$BOD$>$ (beginning of diffusion) and $<$EOD$>$ (end of diffusion), are designed to bridge the two generation methods.
By employing collaborative training to explicitly incorporate knowledge from both generation methods, these two action types reinforce each other and are adaptively ensembled to control the robot arms.
For HybridVLA's output, continuous actions are generated through iterative denoising, while discrete actions are produced autoregressively, all within the next-token prediction process.