HybridVLA:
Collaborative Diffusion and Autoregression
in a Unified Vision-Language-Action Model
Demonstrations
Generalization
Abstract
A central objective of manipulation policy design is to enable robots to comprehend human instructions and predict generalized actions in unstructured environments. Recent autoregressive vision-language-action (VLA) approaches discretize actions into bins to exploit the pretrained reasoning and generation paradigms of vision-language models (VLMs). While these models achieve efficient and scalable training, the discretization undermines the continuity required for precise control. In contrast, diffusion-based VLA methods incorporate an additional diffusion head to predict continuous actions, but they rely solely on feature representations extracted from the VLM, without leveraging the pretrained large language model (LLM) as an expert for iterative action generation. To integrate the complementary strengths of autoregressive and diffusion generation, we introduce HybridVLA, which innovatively leverages a shared LLM backbone to perform iterative action prediction through both paradigms. Specifically, a collaborative training recipe is proposed, incorporating diffusion denoising into the next-token prediction process and mitigating interference between the two generation paradigms. With this recipe, we find these two action prediction methods not only reinforce each other but also exhibit varying strengths across different scenarios. Therefore, we design a collaborative action ensemble mechanism that adaptively fuses both predictions, leading to more robust control. HybridVLA outperforms previous state-of-the-art VLA methods by 17% and 19% in mean success rate on simulation and real-world tasks, respectively, while demonstrating generalization to unseen configurations.
Video
Overview
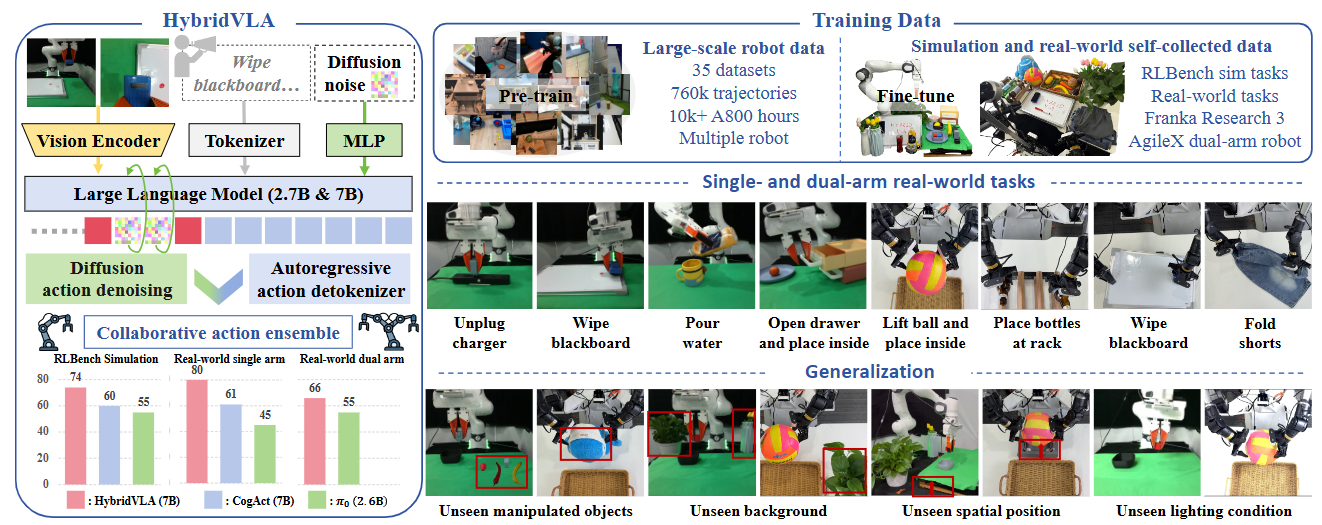
Unlike recent diffusion-based VLA methods that attach a separate diffusion head after VLMs, HybridVLA innovatively integrates diffusion and autoregressive action prediction within a single LLM, embedding the denoising process of diffusion into the next-token prediction. Under our proposed methods, HybridVLA achieves remarkable performance across a wide range of tasks.
HybridVLA Framework
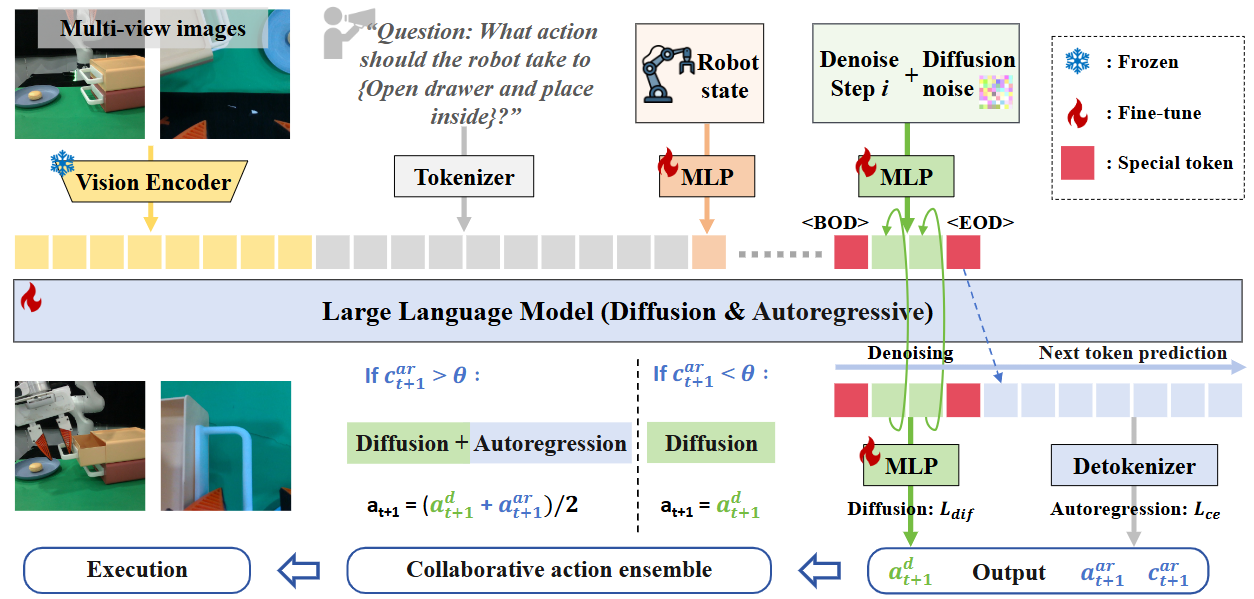
All multimodal inputs are encoded into tokens and subsequently organized into our designed token sequence formulation within the LLM's embedding space. For diffusion tokens, HybridVLA simultaneously projects the denoising timestep and noise into continuous vector representations. The corresponding noisy samples are iteratively fed into the LLM to predict the noise at each step. The marker tokens, $<$BOD$>$ (Beginning of Diffusion) and $<$EOD$>$ (End of Diffusion), are introduced to bridge the two generation paradigms. Subsequently, autoregressive actions are generated via next action-token prediction, explicitly conditioned on the preceding tokens. The two actions can be adaptively ensembled for robot arm control.